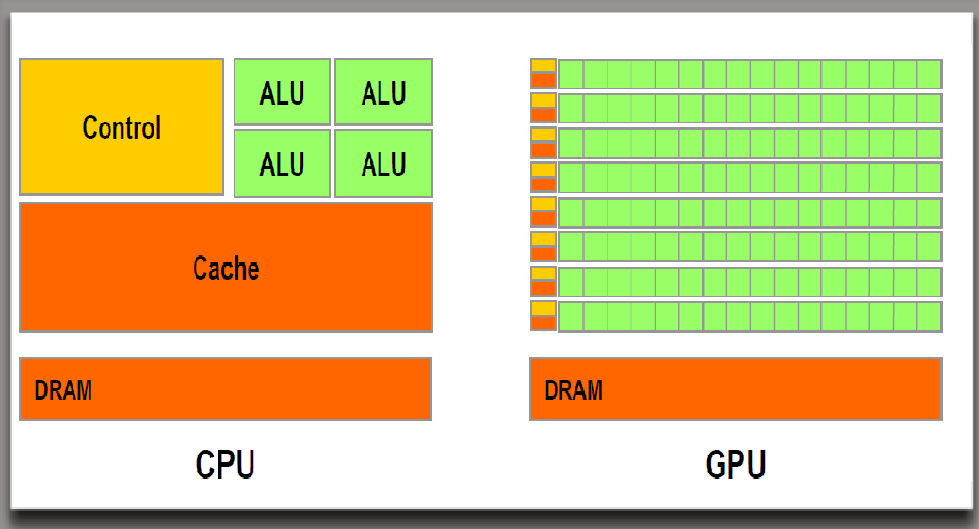
How CPUs and GPUs Identify and Divide Tasks
- Explicit Programming: Programmers explicitly define which parts of the code should run on the CPU and which should run on the GPU. This is typically done using specific programming libraries and frameworks.
- CUDA: For NVIDIA GPUs, CUDA allows programmers to write code that specifies which computations should be executed on the GPU.
- OpenCL: An open standard that supports programming for various hardware platforms, including both CPUs and GPUs.
- Parallel Computing Libraries: Libraries such as OpenMP for CPUs and CUDA for GPUs provide constructs that allow programmers to define parallel regions of code.
- OpenMP: Used for parallel programming on multi-core CPUs.
- CUDA: Used for parallel programming on GPUs, allowing for explicit GPU task allocation.
- API Calls: Graphics APIs such as DirectX and OpenGL are used to offload rendering tasks to the GPU.
- When a program calls a function from these APIs, the corresponding tasks are sent to the GPU for processing.
- Heterogeneous Computing Frameworks: Frameworks like OpenCL and Vulkan allow the distribution of tasks across CPUs and GPUs.
- These frameworks enable programmers to write code that can be executed on multiple types of processors, facilitating task division based on the hardware capabilities.
- Hardware Drivers and Runtime Systems: The drivers and runtime systems for CPUs and GPUs manage task allocation at a low level.
- Drivers: GPU drivers, for instance, include schedulers that manage how and when tasks are executed on the GPU.
- Runtime Systems: These systems can dynamically allocate tasks to the CPU or GPU based on the workload and resource availability.
- Automatic Optimization: Some high-level programming languages and frameworks provide automatic optimization features.
- TensorFlow: In machine learning, frameworks like TensorFlow can automatically use GPUs for training models if available, without requiring explicit instruction from the programmer.
In summary, the division of tasks between CPUs and GPUs is primarily managed through explicit programming, parallel computing libraries, API calls, heterogeneous computing frameworks, hardware drivers, and runtime systems. These methods allow programmers to leverage the strengths of both CPUs and GPUs for efficient computation.